Prompts Quickstart
Try in a Colab Notebook here →
This Quickstart guide will walk you how to use Trace to visualize and debug calls to LangChain, LlamaIndex or your own LLM Chain or Pipeline:
Langchain: Use the 1-line LangChain environment variable or context manager integration for automated logging.
LlamaIndex: Use the W&B callback from LlamaIndex for automated logging.
Custom usage: Use Trace with your own custom chains and LLM pipeline code.
Use W&B Trace with LangChain
Versions Please use wandb >= 0.15.4 and langchain >= 0.0.218
With a 1-line environment variable from LangChain, W&B Trace will continuously log calls to a LangChain Model, Chain, or Agent.
Note that you can also see the documentation for W&B Trace in the LangChain documentation.
For this quickstart, we will use a LangChain Math Agent:
1. Set the LANGCHAIN_WANDB_TRACING environment variable
First, set the LANGCHAIN_WANDB_TRACING environment variable to true. This will turn on automated Weights & Biases logging with LangChain:
import os
# turn on wandb logging for langchain
os.environ["LANGCHAIN_WANDB_TRACING"] = "true"
Thats it! Now any call to a LangChain LLM, Chain, Tool or Agent will be logged to Weights & Biases.
2. Configure your Weights & Biases settings
You can optionally set additional Weights & Biases Environment Variables to set parameters that are typically passed to wandb.init(). Parameters often used include WANDB_PROJECT or WANDB_ENTITY for more control over where your logs are sent in W&B. For more information about wandb.init, see the API Reference Guide.
# optionally set your wandb settings or configs
os.environ["WANDB_PROJECT"] = "langchain-tracing"
3. Create a LangChain Agent
Create a standard math Agent using LangChain:
from langchain.chat_models import ChatOpenAI
from langchain.agents import load_tools, initialize_agent, AgentType
llm = ChatOpenAI(temperature=0)
tools = load_tools(["llm-math"], llm=llm)
math_agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION)
4. Run the Agent and start Weights & Biases logging
Use LangChain as normal by calling your Agent. You will see a Weights & Biases run start and be asked for your Weights & Biases API key. Once your enter your API key, the inputs and outputs of your Agent calls will start to be streamed to the Weights & Biases App.
# some sample maths questions
questions = [
"Find the square root of 5.4.",
"What is 3 divided by 7.34 raised to the power of pi?",
"What is the sin of 0.47 radians, divided by the cube root of 27?",
]
for question in questions:
try:
# call your Agent as normal
answer = math_agent.run(question)
print(answer)
except Exception as e:
# any errors will be also logged to Weights & Biases
print(e)
pass
Once each Agent execution completes, all calls in your LangChain object will be logged to Weights & Biases
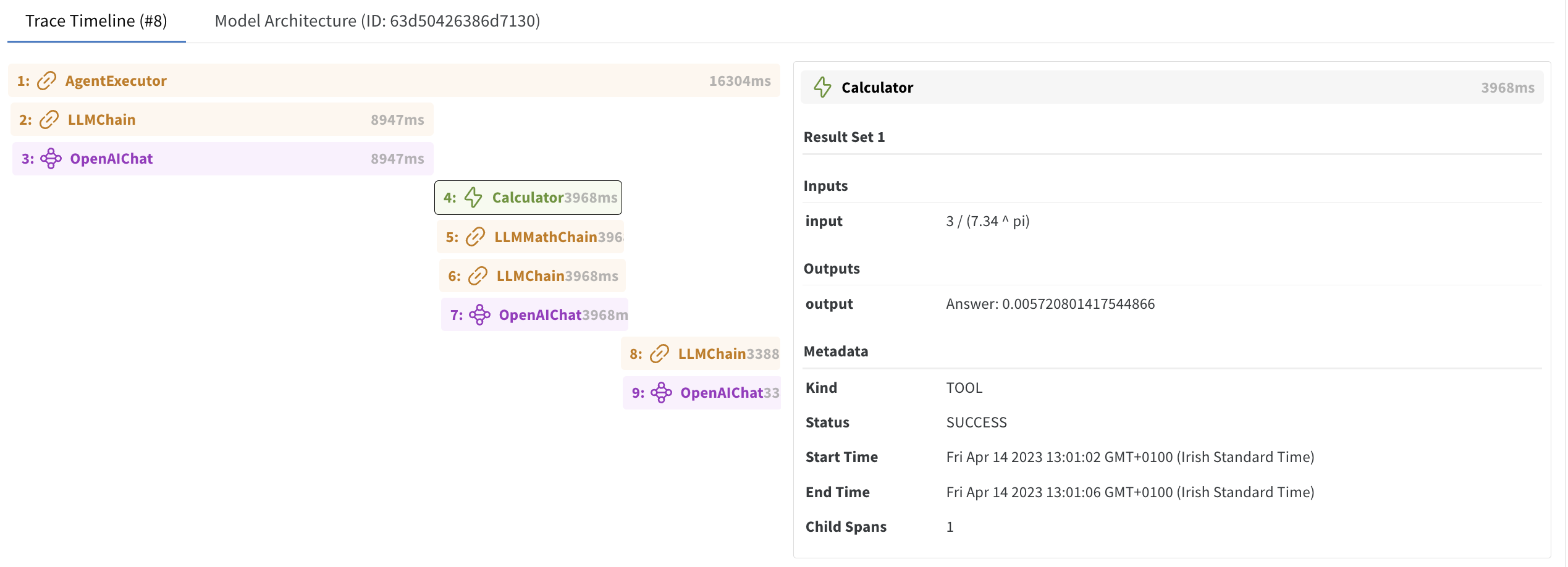
5. View the trace in Weights & Biases
Click on the W&B run link generated in the previous step. This will redirect you to your Project workspace in the W&B App.
Select a run you created to view the trace table, trace timeline and the model architecture of your LLM.
6. LangChain Context Manager
Depending on your use case, you might instead prefer to use a context manager to manage your logging to W&B:
from langchain.callbacks import wandb_tracing_enabled
# unset the environment variable and use a context manager instead
if "LANGCHAIN_WANDB_TRACING" in os.environ:
del os.environ["LANGCHAIN_WANDB_TRACING"]
# enable tracing using a context manager
with wandb_tracing_enabled():
math_agent.run("What is 5 raised to .123243 power?") # this should be traced
math_agent.run("What is 2 raised to .123243 power?") # this should not be traced
Please report any issues with this LangChain integration to the wandb repo with the tag langchain
Use W&B Trace with Any LLM Pipeline or Plug-In
Versions Please use wandb >= 0.15.4
A W&B Trace is created by logging 1 or more "spans". A root span is expected, which can accept nested child spans, which can in turn accept their own child spans. Spans can be of type AGENT, CHAIN, TOOL or LLM.
When logging with Trace, a single W&B run can have multiple calls to a LLM, Tool, Chain or Agent logged to it, there is no need to start a new W&B run after each generation from your model or pipeline, instead each call will be appended to the Trace Table.
In this quickstart, we will how to log a single call to an OpenAI model to W&B Trace as a single span. Then we will show how to log a more complex series of nested spans.
1. Import Trace and start a Weights & Biases run
Call wandb.init to start a W&B run. Here you can pass a W&B project name as well as an entity name (if logging to a W&B Team), as well as a config and more. See wandb.init for the full list of arguments.
Once your start a W&B run you will be asked to log in with your Weights & Biases API key.
import wandb
# start a wandb run to log to
wandb.init(project="trace-example")
You can also set the entity argument in wandb.init if logging to a W&B Team.
2. Log to a Trace
Now we will query OpenAI times and log the results to a W&B Trace. We will log the inputs and outputs, start and end times, whether the OpenAI call was successful, the token usage, and additional metadata.
You can see the full description of the arguments to the Trace class here.
import openai
import datetime
from wandb.sdk.data_types.trace_tree import Trace
openai.api_key = "<YOUR_OPENAI_API_KEY>"
# define your conifg
model_name = "gpt-3.5-turbo"
temperature = 0.7
system_message = "You are a helpful assistant that always replies in 3 concise bullet points using markdown."
queries_ls = [
"What is the capital of France?",
"How do I boil an egg?" * 10000, # deliberately trigger an openai error
"What to do if the aliens arrive?",
]
for query in queries_ls:
messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": query},
]
start_time_ms = datetime.datetime.now().timestamp() * 1000
try:
response = openai.ChatCompletion.create(
model=model_name, messages=messages, temperature=temperature
)
end_time_ms = round(
datetime.datetime.now().timestamp() * 1000
) # logged in milliseconds
status = "success"
status_message = (None,)
response_text = response["choices"][0]["message"]["content"]
token_usage = response["usage"].to_dict()
except Exception as e:
end_time_ms = round(
datetime.datetime.now().timestamp() * 1000
) # logged in milliseconds
status = "error"
status_message = str(e)
response_text = ""
token_usage = {}
# create a span in wandb
root_span = Trace(
name="root_span",
kind="llm", # kind can be "llm", "chain", "agent" or "tool"
status_code=status,
status_message=status_message,
metadata={
"temperature": temperature,
"token_usage": token_usage,
"model_name": model_name,
},
start_time_ms=start_time_ms,
end_time_ms=end_time_ms,
inputs={"system_prompt": system_message, "query": query},
outputs={"response": response_text},
)
# log the span to wandb
root_span.log(name="openai_trace")
3. View the trace in Weights & Biases
Click on the W&B run link generated in step 2. Here you should be able to view the trace table and trace timeline of your LLM.
4. Logging a LLM pipeline using nested spans
In this example we will simulate an Agent being called, which then calls a LLM Chain, which calls an OpenAI LLM and then the Agent "calls" a Calculator tool.
The inputs, outputs and metadata for each step in the execution of our "Agent" is logged in its own span. Spans can have child
import time
# The query our agent has to answer
query = "How many days until the next US election?"
# part 1 - an Agent is started...
start_time_ms = round(datetime.datetime.now().timestamp() * 1000)
root_span = Trace(
name="MyAgent",
kind="agent",
start_time_ms=start_time_ms,
metadata={"user": "optimus_12"},
)
# part 2 - The Agent calls into a LLMChain..
chain_span = Trace(name="LLMChain", kind="chain", start_time_ms=start_time_ms)
# add the Chain span as a child of the root
root_span.add_child(chain_span)
# part 3 - the LLMChain calls an OpenAI LLM...
messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": query},
]
response = openai.ChatCompletion.create(
model=model_name, messages=messages, temperature=temperature
)
llm_end_time_ms = round(datetime.datetime.now().timestamp() * 1000)
response_text = response["choices"][0]["message"]["content"]
token_usage = response["usage"].to_dict()
llm_span = Trace(
name="OpenAI",
kind="llm",
status_code="success",
metadata={
"temperature": temperature,
"token_usage": token_usage,
"model_name": model_name,
},
start_time_ms=start_time_ms,
end_time_ms=llm_end_time_ms,
inputs={"system_prompt": system_message, "query": query},
outputs={"response": response_text},
)
# add the LLM span as a child of the Chain span...
chain_span.add_child(llm_span)
# update the end time of the Chain span
chain_span.add_inputs_and_outputs(
inputs={"query": query}, outputs={"response": response_text}
)
# update the Chain span's end time
chain_span._span.end_time_ms = llm_end_time_ms
# part 4 - the Agent then calls a Tool...
time.sleep(3)
days_to_election = 117
tool_end_time_ms = round(datetime.datetime.now().timestamp() * 1000)
# create a Tool span
tool_span = Trace(
name="Calculator",
kind="tool",
status_code="success",
start_time_ms=llm_end_time_ms,
end_time_ms=tool_end_time_ms,
inputs={"input": response_text},
outputs={"result": days_to_election},
)
# add the TOOL span as a child of the root
root_span.add_child(tool_span)
# part 5 - the final results from the tool are added
root_span.add_inputs_and_outputs(
inputs={"query": query}, outputs={"result": days_to_election}
)
root_span._span.end_time_ms = tool_end_time_ms
# part 6 - log all spans to W&B by logging the root span
root_span.log(name="openai_trace")
Once you have logged your span, you will be able to see your Trace table update in the W&B App.
Use W&B Trace with LlamaIndex
Versions Please use wandb >= 0.15.4 and llama-index >= 0.6.35
At the lowest level, LlamaIndex uses the concept of start/end events (CBEventTypes) to keep a track of logs. Each event has some payload which provides information like, the query asked and the response generated by the LLM, or about the number of documents used to create N chunks, etc.
At a higher level, they have recently introduced the concept of Callback Tracing which builds a trace map of connected events. For example when you query over an index, under the hood, retrieval, LLM calls, etc. takes place.
The WandbCallbackHandler provides an intuitive way to visualize and track this trace map. It captures the payload of the events and logs them to wandb. It also tracks necessary metadata like total token counts, prompt, context, etc.
Moreover, this callback can also be used to upload and download indices to/from W&B Artifacts for version controlling your indices.
1. Import WandbCallbackHandler
First import the WandbCallbackHandler and set it up. You can also pass additional parameters wandb.init parameteres such as your W&B Project or Entity.
You will see a W&B run start and be asked for your Weights & Biases API key. A W&B run link will be generated, here you'll be able to view your logged LlamaIndex queries and data once you start logging.
from llama_index import ServiceContext
from llama_index.callbacks import CallbackManager, WandbCallbackHandler
# initialise WandbCallbackHandler and pass any wandb.init args
wandb_args = {"project": "llamaindex"}
wandb_callback = WandbCallbackHandler(run_args=wandb_args)
# pass wandb_callback to the service context
callback_manager = CallbackManager([wandb_callback])
service_context = ServiceContext.from_defaults(callback_manager=callback_manager)
2. Build an Index
We will build a simple index using a text file.
docs = SimpleDirectoryReader("path_to_dir").load_data()
index = GPTVectorStoreIndex.from_documents(docs, service_context=service_context)
3. Query an index and start Weights & Biases logging
With the loaded index, start querying over your documents. Every call to your index will be automatically logged to Weights & Biases
questions = [
"What did the author do growing up?",
"Did the author travel anywhere?",
"What does the author love to do?",
]
query_engine = index.as_query_engine()
for q in questions:
response = query_engine.query(q)
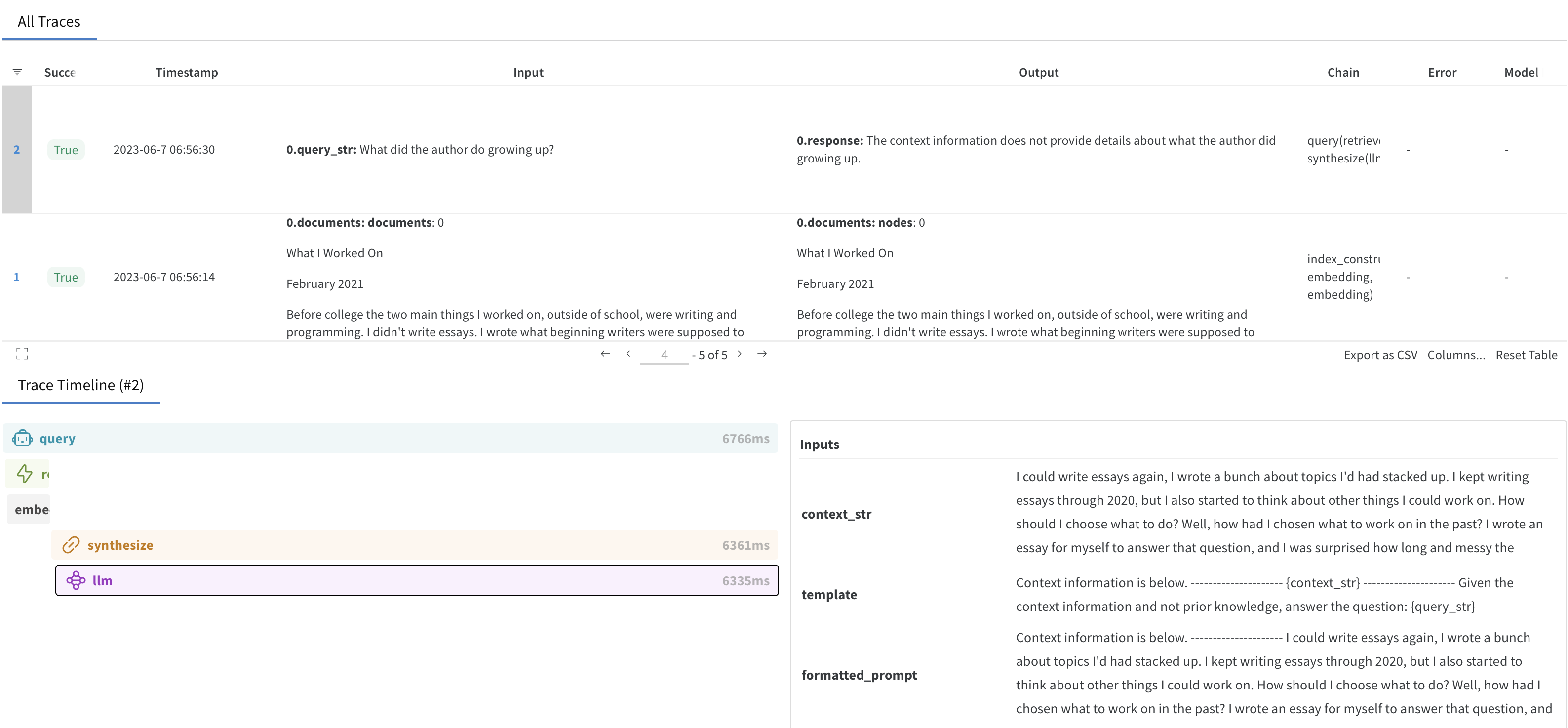
4. View the trace in Weights & Biases
Click on the Weights and Biases run link generated while initializing the WandbCallbackHandler in step 1. This will take you to your project workspace in the W&B App where you will find a trace table and a trace timeline.
5. Finish tracking
When you are done tracking your LLM queries, it is good practice to close the wandb process like so:
wandb_callback.finish()
Thats it! Now you can log your queries to your index using Weights & Biases. If you come across any issues, please file an issue on the wandb repo with the tag llamaindex
6. [Optional] Save your Index data in Weights & Biaes Artifacts
Weights & Biases Artifacts is a versioned data and model storage product.
By logging your index to Artifacts and then using it when needed, you can assosciate a particular version of your index with the logged Trace outputs, ensuring full visibility into what data was in your index for a particular call to your index.
# The string passed to the `index_name` will be your artifact name
wandb_callback.persist_index(index, index_name="my_vector_store")
You can then go to the artifacts tab on your W&B run page to view the uploaded index.
Using an Index stored in W&B Artifacts
When you load an index from Artifacts you'll return a StorageContext. Use this storage context to load the index into memory using a function from the LlamaIndex loading functions.
from llama_index import load_index_from_storage
storage_context = wandb_callback.load_storage_context(
artifact_url="<entity/project/index_name:version>"
)
index = load_index_from_storage(storage_context, service_context=service_context)
Note: For a ComposableGraph the root id for the index can be found in the artifact's metadata tab in the W&B App.
Next Steps
- You can use existing W&B features like Tables and Runs to track LLM application performance. See this tutorial to learn more: Tutorial: Evaluate LLM application performance